


KI ist kein Zauberstab, der aus dem Nichts erscheint. Sie ist eigentlich die Fortführung dessen, was wir schon seit Jahren machen: Wir bringen Ordnung in unsere Daten. Deshalb erkläre ich Begriffe wie API und Datenformate.
Ohne Fundament kein Haus
Im Evangelium heißt es sinngemäß, dass ein kluger Mann sein Haus auf Fels baut. Für die KI ist dieser „Fels“ die Digitalisierung. Damit eine KI uns im Alltag helfen kann – sei es beim Sortieren von Fotos oder beim Verstehen von Gebrauchsanweisungen –, braucht sie „maschinenlesbare Daten“.
Ist ja auch logisch: Informationen für die KI müssen so gespeichert sein, dass ein Computer sie versteht. Ein Foto von einem handgeschriebenen Einkaufszettel kann ein Computer zwar anzeigen, aber er versteht den Inhalt erst, wenn wir ihn in ein Format bringen, das er „lesen“ kann.
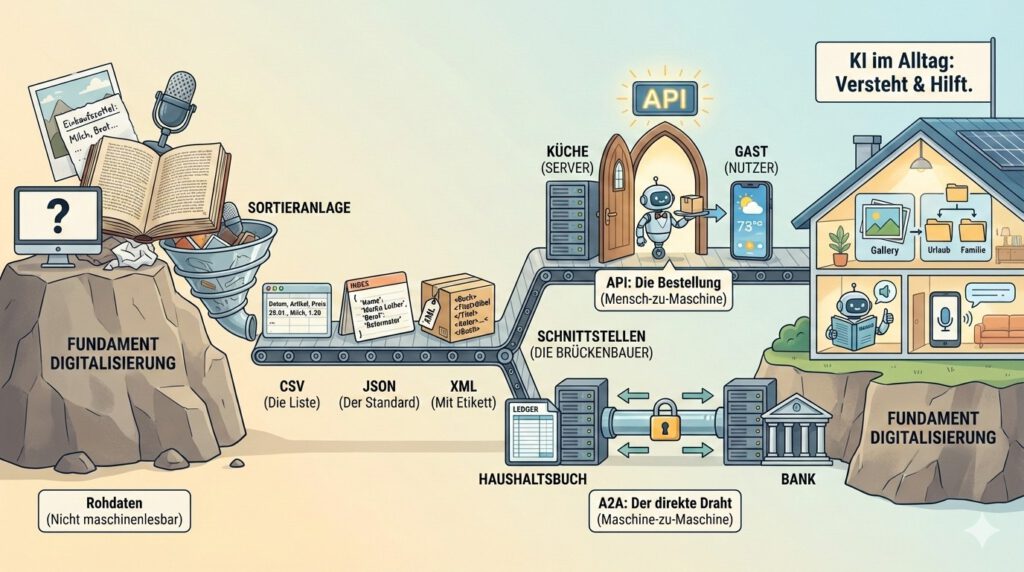
1. Datenformate: Der „Umschlag“, in dem die Info steckt
Damit die KI oder ein anderes Programm die Daten lesen kann, müssen sie in einer bestimmten Struktur vorliegen. Ein handgeschriebener Brief ist für uns schön, für den Computer aber schwer „verdaulich“. Er braucht es strukturierter:
- CSV (Comma Separated Values): Das ist die einfachste Form, quasi eine digitale Liste. Stell dir eine Excel-Tabelle vor, bei der alle Infos nur durch Kommas getrennt sind. Das kann jedes Programm lesen.
- JSON (JavaScript Object Notation): Das ist heute das wichtigste Format im Internet. Es sieht fast aus wie ein kleiner Katechismus: Es gibt immer eine Frage (einen Schlüssel) und eine Antwort (den Wert).
- Beispiel:
{"Name": "Martin Luther", "Beruf": "Reformator"}. Das ist für eine KI extrem leicht zu sortieren.
- Beispiel:
- XML: Etwas älter, aber sehr stabil. Hier werden Informationen mit „Etiketten“ (Tags) beklebt, ähnlich wie wir in der Bibliothek Bücher nach Kategorien ordnen.
- (Mehr dazu unter Abschnitt 3.)
2. Schnittstellen: Die Brückenbauer
Damit die KI oder ein anderes Programm auf die Daten zugreifen kann, braucht sie eine Schnittstelle. Stell dir eine Schnittstelle wie ein Tür in die Kirche vor: Du musst nicht durchs Dach einsteigen oder vor der Wand stehen bleiben, durch die Tür kannst du einfach hereinkommen und mit uns Gottesdienst feiern. Die „Schnittstelle““ ist die definierte Öffnung, durch die du Zugang findest. Eine Tür zur Datenverarbeitung ist zum Beispiel die Webseite Wikipedia. Du brauchst kein Konto und kein Abo, aber auf der Webseite gibst du Daten ein und bekommst Daten angezeigt. Im Hintergrund deiner Webseite oder einer APP braucht es aber eine technische Schnittstellen wie API und A2A.
API (Application Programming Interface)
Das ist heute der Standard. Man kann sich eine API wie eine digitale Speisekarte vorstellen. Du bist der Gast (der Nutzer), die Küche ist das Programm (z. B. deine Bank-App). Du schaust auf die Karte, bestellst etwas, und der Kellner (die API) bringt deine Bestellung in die Küche und liefert dir das Ergebnis zurück.
- Alltagsbeispiel: Wenn du auf einer Wetter-Website deine Postleitzahl eingibst, nutzt diese Seite eine API, um die Daten direkt vom Wetterdienst abzurufen.
Die Schnittstelle kann generell offen sein oder auch nur mit einem Schlüssel zu öffnen.
A2A (Application-to-Application)
Hierbei geht es um die direkte Kommunikation zwischen zwei Anwendungen, ohne dass wir als Menschen dazwischenklicken müssen. Es ist wie ein Dauerauftrag bei der Bank: Ein System sagt dem anderen automatisch Bescheid, wenn sich etwas ändert.
- Alltagsbeispiel: Dein digitales Haushaltsbuch zieht sich jede Nacht automatisch die Kontobewegungen von deiner Bank-App, damit du am Morgen eine aktuelle Übersicht hast.
Da die KI so sehr selbstständig handeln kann, sind besondere Sicherheitsvorkehrungen wichtig.
3. Warum ist das für dich wichtig?
Vielleicht denkst du: „Warum muss ich das wissen?“ Je mehr wir verstehen, dass Daten nicht einfach eine Abfolge von Nullen und Einsen sind, sondern eine klare Ordnung (Struktur) brauchen, und durch welche Tür wir Zugang bekommen, desto besser können wir die Werkzeuge nutzen, die uns den Alltag erleichtern. Dann wird auch klarer, dass die Türen nicht immer offen stehen sollten, sondern besser mit einem Schlüssel gesichert werden.
Kurz, Ordnung hilft – auch in der digitalen Welt!
Nicht nur der Name einer Datei ist wichtig, sondern auch die Endung, die das Format benennt. Es wird immer wichtiger für die Datenablage auf genau diese Formate zu achten.
Wenn zum Beispiel deine Fotos auf dem Smartphone heute automatisch nach „Urlaub 2023“ oder „Enkelkinder“ sortiert werden, dann nur, weil im Hintergrund eine API die Bilder an eine KI schickt, die das Datenformat des Bildes (genauer die Metadaten) liest und auswertet.
Weil die Formate nach und nach entwickelt wurden, verstehen sich die unterschiedlichen Programme oft nicht. Man braucht Übersetzer oder eine bessere Standarisierung. Manchmal erzeugt diese digitale Sprachverwirrung auch tiefen Frust. Aber was hilft es? Sicher kennst du schon einige dieser wichtigste und aktuellen Formate:
A. Textformate
Text ist nicht gleich Text. In der Datenverarbeitung unterscheiden wir zwischen unstrukturierten und (semi-)strukturierten Daten.
- TXT (.txt): Der nackte Standard. Keine Formatierung, nur Zeichen. Perfekt für Logfiles.
- MicrosoftWord-Dokument (.doc / .docx): Das bekannteste Mammut mit vielen Formatierungsanweisungen in einem Text mit Überschriften, automatischen Inhaltsverzeichnisssen, Tabellen, Bildern …
- CSV (.csv): Das Arbeitstier für Tabellen. Simpel, universell lesbar und unverzichtbar für Data Science und Excel-Exporte.
- JSON (.json): Der Goldstandard im Web. Leichtgewichtig und ideal für den Datenaustausch zwischen Browser und Server.
- XML (.xml): Der strukturierte (aber etwas geschwätzige) große Bruder von JSON. Oft in älteren Systemen oder für Konfigurationsdateien genutzt.
- Markdown (.md): Text mit einfachen Formatierungshilfen. Beliebt bei Entwicklern für Dokumentationen.
- PDF (.pdf): Eigentlich ein „Container“ für die Darstellung. Schwer zu verarbeiten, aber ein Standard für den Dokumentenaustausch.
B. Bildformate
Hier dreht sich alles um das Gleichgewicht zwischen Dateigröße und Bildqualität.
- JPEG/JPG: Der Klassiker. Hohe Kompression, aber verlustbehaftet. Ideal für Fotos im Web.
- PNG: Verlustfrei und unterstützt Transparenz. Ein Muss für Logos und Grafiken mit harten Kanten.
- WebP: Googles moderner Nachfolger für JPEG/PNG. Bietet bessere Kompression bei gleicher Qualität.
- SVG: Vektorbasiert. Besteht aus mathematischen Formeln statt Pixeln. Unendlich skalierbar ohne Qualitätsverlust.
- TIFF: Das Schwergewicht für Druck und Archivierung. Riesige Dateien, aber maximale Qualität.
C. Videoformate
Bei Videos ist es wichtig, zwischen dem Container (die Dateiendung) und dem Codec (die Kompressionstechnologie) zu unterscheiden.
- MP4 (.mp4): Der Alleskonner. Nutzt meist den H.264 oder H.265 Codec. Läuft auf fast jedem Toaster.
- MKV (.mkv): Der „Allesfresser“. Kann unendlich viele Tonspuren, Untertitel und Metadaten in einer Datei speichern.
- MOV: Apples Standardformat. Hochwertig, oft in der professionellen Videobearbeitung genutzt.
- WebM: Das offene Format für das Web (YouTube nutzt das intensiv), optimiert für Streaming im Browser.
D. Audioformate
Die ewige Schlacht: Hörst du den Unterschied zwischen einer MP3 und einer verlustfreien Datei?
- MP3: Der Veteran. Verlustbehaftet, aber klein genug, um tausende Songs in der Hosentasche zu haben.
- WAV: Unkomprimiertes Audio. Wird oft in der Produktion verwendet, weil es keine Informationen „wegwirft“.
- FLAC: Die „Zip-Datei“ für Audio. Verlustfreie Kompression – volle Qualität bei halber Dateigröße im Vergleich zu WAV.
- AAC: Der Nachfolger von MP3 (Standard bei Apple). Bessere Qualität bei gleicher Bitrate.
4. Die Zukunft
Für die Welt der Künstlichen Intelligenz und insbesondere für KI-Agenten (autonome Systeme, die Aufgaben planen und ausführen) verschiebt sich der Fokus. Es geht nicht mehr nur darum, dass wir Menschen die Daten lesen können, sondern dass Maschinen sie effizient, sicher und strukturiert verarbeiten.

Hier sind die Formate, die für die KI den Ton angeben:
Für das Training und Big Data (Die „Nahrung“)
Wenn KI-Modelle trainiert werden oder Agenten auf riesige Datenbanken zugreifen, zählt Geschwindigkeit und Kostenersparnis beim Speichern.
- Parquet (.parquet): Das bevorzugte Format für große Datensätze. Es speichert Daten spaltenorientiert (columnar storage), was extrem schnelle Abfragen ermöglicht. Wenn ein Agent nur eine bestimmte Information aus Milliarden Zeilen braucht, ist Parquet der Goldstandard.
- JSONL (.jsonl – JSON Lines): Im Gegensatz zu normalem JSON besteht dieses Format aus einer JSON-Objekt-Struktur pro Zeile. Das ist entscheidend für das Streaming von Daten. Ein Modell kann so Terabytes an Text verarbeiten, ohne die gesamte Datei auf einmal in den Arbeitsspeicher laden zu müssen.
Für das Modell-Management (Die „Gewichte“)
Wie ein KI-Modell gespeichert wird, hat sich aus Sicherheitsgründen massiv gewandelt.
- Safetensors (.safetensors): Hat das alte „Pickle“-Format fast vollständig abgelöst. Warum? Pickle konnte Schadcode ausführen, wenn man ein Modell heruntergeladen hat. Safetensors speichert nur die reinen mathematischen Gewichte (Tensoren) – es ist sicherer und schneller beim Laden.
- GGUF: Das Standardformat für lokale KI (wenn du z. B. Llama oder Mistral auf deinem Laptop ausführst). Es erlaubt „Quantisierung“, wodurch riesige Modelle so verkleinert werden, dass sie auf handelsüblicher Hardware laufen, ohne viel Intelligenz zu verlieren.
- ONNX (.onnx): Ein offenes Format, das es ermöglicht, Modelle zwischen verschiedenen Frameworks (wie PyTorch und TensorFlow) auszutauschen. Wichtig für die Integration von KI in Apps.
Für die Kommunikation von Agenten (Das „Werkzeug“)
Agenten müssen mit anderen Programmen sprechen, um z. B. einen Flug zu buchen oder eine E-Mail zu schreiben.
- JSON (für Tool-Calling): Wenn ein Agent ein Tool benutzt (z. B. eine Websuche), schickt er die Parameter fast immer als JSON. Es ist die universelle Sprache der APIs.
- Markdown (.md): Überraschenderweise eines der wichtigsten Formate für die Ausgabe. KI-Modelle „denken“ oft besser in Markdown, da die klare Struktur (Überschriften, Listen) ihnen hilft, den logischen Faden nicht zu verlieren.
- MCP (Model Context Protocol): Ein brandneuer Standard (2025/2026), der es Agenten erlaubt, sich universell mit Datenquellen (Google Drive, GitHub, Slack) zu verbinden, ohne für jeden Dienst eine eigene Schnittstelle bauen zu müssen.
Für die Echtzeit-Verarbeitung (Das „Nervensystem“)
- Apache Arrow: Ein Speicherformat, das Daten im RAM so organisiert, dass sie ohne Konvertierung zwischen verschiedenen KI-Tools hin- und hergereicht werden können. Das spart extrem viel Zeit bei der Live-Analyse von Daten.
- Protobuf: Googles binäres Format für die superschnelle Kommunikation zwischen Microservices. Wenn Agenten in einem Schwarm (Multi-Agent-Systems) miteinander flüstern, nutzen sie oft Protobuf, weil es viel kompakter ist als JSON.